Appearance
FULLSTACK
Termi stack tarkoittaa sovelluskehitysprojektissa käytettyihin tekniikoihin. Nykypäivänä sovellukset ovat todella monimutkaisia kokonaisuuksia, jotka voivat koostua useista pienistä mikroserviseistä, joiden väliseen kommunikaatioon on käytetty useita erilaisia tekniikoita ja protokollia (esim. REST, SOAP, GraphQL, gRPC yms.) ja useita eri ohjelmointikieliä. Nämä kaikki tekniikat muodostavat sovelluskehitysprojektin stackin.
Varsinkin web-kehitysprojekteissa stack jaetaan frontendiin ja backendiin.
FRONTEND (ASIAKASSOVELLUS)
Frontend keskittyy käyttöliittymän, eli käyttäjälle näkyvän osan, kehittämiseen ja siinä tulevat mukaan UI/UX-suunnittelu. Frontend-kehittäjät työskentelevät HTML:n, CSS:n ja JavaScriptin parissa ja ovat vastauussa käyttöliittymäsuunnitelman käytännön toteutuksesta. Frontendia koodatessa voidaan käyttää useasti erilaisia kehystyötkaluja ja kirjastoja, kuten React, Vue, Angular ja Svelte
BACKEND (TAUSTAPALVELU)
Backend puolestaan keskittyy ohjelmiston logiikaan ja rakenteeseen. Backendin kehittäjät vastaavat useasti ohjelmiston tiedon varastoinnista (tietokanta) tiedon prosessoinnista sekä tietoturvasta ja frontin ja backendin välisen rajapinnan rakentamisesta, jotta frontendit (esim. web- ja puhelinsovellukset) voivat hakea tarvitasemansa tiedon backendista. Backendia voidaan koodata esim. Pythonilla, C#:lla JavaScriptillä (Node.js), PHP:llä, Golla jne.
INFO
Tietoturva on toki osa koko sovelluskehitysprosessia ja vaikuttaa kaikilla fullstackin osa-alueilla, mutta tietoturva on varsin oleellinen osa taustapalvelun koodausta, koska taustapalvelu huolehtii istunnoista, JWT-tunnisteista, evästeistä yms.
Jos frontend / backend-jaottelua vertaa autoon, niin backend on moottori ja voimansiirto ja frontend on hallintalaitteet, kori ja maalipinta.
Perinteinen fullstackin jakaminen pelkkään frontendiin ja backendiin on melko rajoittava ja suppea, sillä nykyään ohjelmistoprojekteissa on hyvin tärkeänä osana mukana myös CI/CD
CI/CD
Aikoinaan ohjelmistojen uusien versioiden julkaisu saattoi kestää päiviä tai viikkoja. Yrityksille, joille nämä ohjelmistot ovat osa ydinliiketoimintaa, tämä tarkoitti hitaiden prosessien vuoksi suoraa rahan menetystä. Nykyään kaikki uudet bugikorjaukset ja päivitykset on tarkoitus testata, integroida osaksi olemassa olevaa järjestelmää ja julkaista välittömästi ilman näkyviä katkoksia palvelussa. CI (Continuous Integration) tarkoittaa jatkuvaa integraatiota ja CD (Continuous Deployment) puolestaan jatkuvaa julkaisua. CI/CD:n keskeisenä työkaluna toimii versionhallintatyökalu (esim. Github tai Gitlab).
// TODO: tähän joku naseva kuva devopsista??? // TODO: Matias, otahan kantaa tähän, laajenna ja korjaa tämä, jos tässä on lisättävää tai jotaki häikkää
CI/CD:n integraatio (CI) voi mennä esimerkiksi näin:
- Kun koodari lisää tekemänsä koodin versionhallintaan (push) ominaisuutta varten kirjoitetut yksikkötestit (koodari kirjoittaa yksikkötestit) ajetaan automaattisesti. Jos yksikkötestit suoritetaan onnistuneesti, voidaan suorittaa integraatiotestit
- Siinä missä yksikkötestien tarkoitus on testata esimerkiksi yksittäisten metodien / funktioiden toimintaa, integraatiotestien tarkoitus on varmistaa, etteivät uudet omainaisudet tai vanhoihin ominaisuuksiin tehdyt muutokset riko muita olemassa olevia ominaisuuksia.
- Jos integraatiotestit suoritetaan onnistuneesti, voidaan siirtyä CD-vaiheeseen, jossa ohjelmisto paketoidaan ja julkaistaan automaattisesti.
Jos näistä kohdista mikään epäonnistuu, voidaan tästä lähettää esim. sähköpostiviesti muutoksen pushanneelle koodarille, joka tutkia, mistä ongelma johtuu ja aloittaa kierroksen alusta.
ARKKITEHTUURIT
Erilaisia sovellusarkkitehtuureja on varmasti kymmeniä ja niiden läpikäymiseen tarvitsisi kokonaisen opintojakson. Keksitymme tällä opintojaksolla niihin arkkitehtuureihin, joita käytämme opintojakson ohjelmistoprojektissa
LAYERED PATTERN
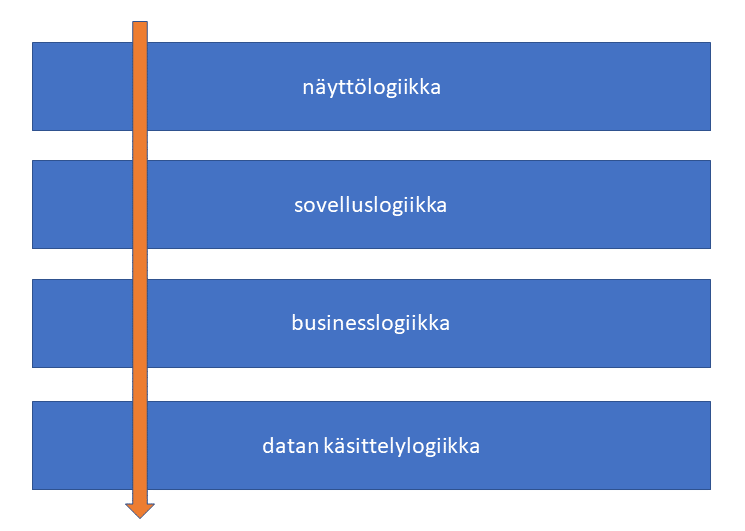 Esimerkki layered patternista
Esimerkki layered patternista
Yo. kuva ei tarkoita, että kaikissa järjestelmissä on juuri samanlainen vastuujako. Joissakin pienissä järjestelmissä voi olla vähemmän kerroksia ja isommissa järjetelmissä taas useampia. Olennaista layered patternissa on, että pyyntö kulkee näyttölogiikkakerrokselta alaspäin. Näyttölogiikkakerros voi siis aloittaa metodin suorituksen sovelluslogiikassa, joka vuorostaan kutsuu toista metodia alemmassa kerroksessa. Ylhäältä pääsee siis alaspäin, mutta alapuolella oleva kerros ei voi ikinä kutsua metodia tai suorittaa käskyjä yläpuolella olevalta kerrokselta. Lyhyesti sanottuna tässä on kyse vastuunjaosta (Separation of Concerns). Tärkeää on myös suunnitella järjestelmä niin, että ylempien kerrosten ei tarvitse välittää siitä, miten tieto alemmalta kerrokselta tulee, kunhan se tulee perille.
NÄYTTÖLOGIIKKA
Kerros, jossa on 'valmiiksi pureskeltu tieto', joka näytetään asiakkaalle. Tieto voi olla esim. HTML, XML tai JSON-formaatissa. Tieto tulee näyttökerrokselle sovelluslogiikalta, joka huolehtii siitä, että tieto on oikeassa formaatissa. Näyttölogiikan ei tarvitse huolehtia formaatista, ainoa tehtävä on näyttää se.
SOVELLUSLOGIIKKA
Sovelluslogiikka voi olla esimerkiksi REST-rajapinnan resurssilogiikkakerros, joka pitää huolen siitä, että oikeat resurssit on kiinnitetty oikeisiin URLeihin. Tämä kerros voi huolehtia esim. siitä, että HTTP-pyynnön Accept-headerin arvo voi vaikuttaa siihen, missä formaatissa tieto viedään näyttölogiikalle.
BUSINESSLOGIIKKA
Businesslogiikkakerroksessa voi olla esimerkiksi liiketoiminnalle ominainen logiikka. Esimerkiksi kirjaston lainausjärjestelmän businesslogiikka on varmasti aivan erilainen kuin sairaalassa käytetyn potilastietojärjestelmän. Molemmissaa järjestelmissä on käyttäjiä, jotka käsittelevät ihmisten tietoja, mutta sovellusten käyttötarkoitus on ihan erilainen.
DATAN KÄSITTELYLOGIIKKA
Datan käsittelylogiikka sisältää tietokantakyselyt. Tämä kerros on toki riippuvainen käytetystä tietokannasta, koska esimerkiksi relaatiotietokantoihin toimivat SQL-kyselyt ovat täysin erilaisia verrattuna NoSQL-tietokantojen kyselykieliin, mutta olennaista on se, että businesslogiikka ei muutu eikä businesslogiikkakerrosta kiinnosta vähääkän, millainen datankäsittelykerros on ja mistä tietokannastea data tulee.
CLIENT-SERVER
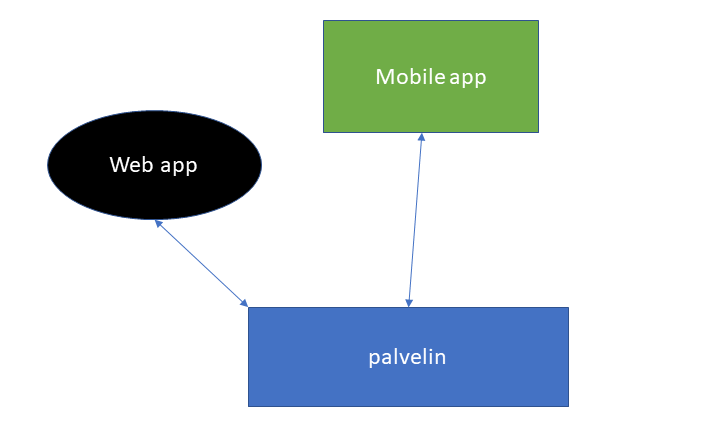 Esimerkki client-server -patternista
Esimerkki client-server -patternista
Layered pattern ja client-server-pattern eivät ole toistensa poissulkevia malleja, vaan molemmat voivat olla käytössä yhdessä ja samassa järjestelmässä. Yo. layered patternin esiemerkki kuvaa esimerkiksi backendin rakennetta tarkemmin ja client-server kuvaa kokonaisarkkitehtuuria paljon yleisemmällä tasolla.
Palvelin kuuntelee jossakin osoitteesa ja portissa (esim. https://esimerkkisivu.fi:8086) asiakkailta tulevia pyyntöjä (HTTP-sanomia), joihin sitten vastaa sen mukaan, mitä asiakassovellus pyytää palvelinta tekemään.
MVC (Model-View-Controller)
MVC-malli on alunperin ollut käytössä työpöytäsovelluksissa, mutta vastuuaelueidensa vuoksi se sopii web-arkkitehtuuriin todella hyvin ja onkin siksi web-ohjelmoinnissa paljon käytetty malli.
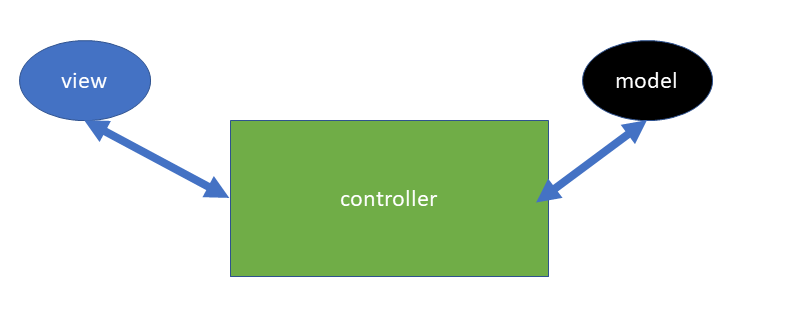
MVC-malli on helpommin ymmärrettävissä, jos kirjaimet laittaa toiseen järjestykseen: VCM
VIEW
View on käyttäjälle näkyvä kerros (webbisivu)
CONTROLLER
Controller-kerroksen tehtävä on ottaa vastaan viewiltä tulevat pyynnöt ja välittää ne Model-kerrokselle. Kun model-palauttaa pyydetyn tiedon, Controller ottaa sen vastaan ja palauttaa tiedon takaisin viewille visualisoitavassa muodossa.
MODEL
Model on koodivastine tietokannan taululle. Jos sinulla on esimerkiksi ao. kuvan mukainen tietokantataulu, jonka nimi on vaikka forms,

sitä vastaava Model voisi olla esim. tällainen
python
class Form:
id = Column(Integer, primary_key=True, server_default=text("nextval('\"InspectionForm_id_seq\"'::regclass)"))
spaceId = Column(ForeignKey('Space.id', ondelete='RESTRICT', onupdate='CASCADE'), nullable=False)
createdAt = Column(TIMESTAMP(precision=3), nullable=False, server_default=text("CURRENT_TIMESTAMP"))
closedAt = Column(TIMESTAMP(precision=3))
createdById = Column(ForeignKey('User.id', ondelete='RESTRICT', onupdate='CASCADE'), nullable=False)
inspectionTypeId = Column(ForeignKey('InspectionType.id', ondelete='RESTRICT', onupdate='CASCADE'), nullable=False)class Form:
id = Column(Integer, primary_key=True, server_default=text("nextval('\"InspectionForm_id_seq\"'::regclass)"))
spaceId = Column(ForeignKey('Space.id', ondelete='RESTRICT', onupdate='CASCADE'), nullable=False)
createdAt = Column(TIMESTAMP(precision=3), nullable=False, server_default=text("CURRENT_TIMESTAMP"))
closedAt = Column(TIMESTAMP(precision=3))
createdById = Column(ForeignKey('User.id', ondelete='RESTRICT', onupdate='CASCADE'), nullable=False)
inspectionTypeId = Column(ForeignKey('InspectionType.id', ondelete='RESTRICT', onupdate='CASCADE'), nullable=False)tai tällainen
go
type Form struct {
Id int
SpaceId int
CreatedAt time.Time
ClosedAt *time.Time
CreatedById int
InspectionTypeId int
}type Form struct {
Id int
SpaceId int
CreatedAt time.Time
ClosedAt *time.Time
CreatedById int
InspectionTypeId int
}Se tapa, jolla model tehdään vaihtelee tietenkin käytettävän kielen ja työkalujen mukaan, mutta oleellista on se, että ne ovat ohjelmallinen vastine tietokantataululle. Monesti tietokantataulut nimetään monikossa, koska ne sisältävät useita rivejä, mutta Model-objektit ovat kuvaus yhden tietokantarivin tiedoista (columneista) ja näin ollen ovat monesti yksikössä.
INFO
Nämä nimeämiskäytännöt eivät ole pakollisia, mutta paljon käytettyjä.
Jos MVC-mallin suhteuttaa ylläkuvattuun layered patterniin, niin M kuvastaa osittain businesslogiikkaa ja datan käsittelykerrosta. Se on osa businesslogiikkakerrosta siksi, että tietokanta ja modelit sen myötä vaihtuvat businesslogiikan mukaan ja datan käsittelykerroksen osa se on siksi, että sen avulla voidaan abstraktoida tietokantakyselyjä.
C on taas osa leyered patternin sovelluslogiikkaa, koska Controllerissa sijaitsevat sovelluslogiikan pyyntöjen käsittelijät. Pienissä järjestelmissä voidaan suoraan Controllerista kutsua Model-kerroksen tietokantahakuja, jolloin Controller käytännössä yhdistää sovelluslogiikan, businesslogiikan ja datan käsittelylogiikan toisiinsa.
Vähänkään isommissa järjestelmissä (tai järjestelmissä, joiden odotetaan kasvavan ajan myötä) näin yksinkertainen jako voi johtaa vaikeasti luettavaan ja jatkokehitettävään koodiin.
INFO
Näistä tulee myöhemmin koodatessa käytännön esimerkkejä.
Kaikissa yllä kuvatuissa malleissa on kuvattu samanlainen järjesetlmä eri näkökulmista ja eri tarkuuksilla, mutta siitä huolimatta kaikissa patterneissa on pohjimmiltaan kyse vastuujaosta.