Appearance
HTTP(S) (HyperTextTransferProtocol)
HTTP-protokolla
Löydät täältä yleiskatsauksen HTTP-protokollasta: https://developer.mozilla.org/en-US/docs/Web/HTTP/Overview
HTTP-protokolla toimii lähtökohtaisesti pyyntö-vastaus-periaatteella (request-response). Eli asiakas (esim. web-selain tai toinen web-palvelin) lähettää pyynnön osoitteeseen (esmi. https://google.com) ja saa palvelimelta vastauksena HTML-dokumentin. Vastauksen ei tarvitse välttämättä olla HTML-dokumentti, vaan se voi olla esimerkiksi XML- tai JSON-formaatissa.
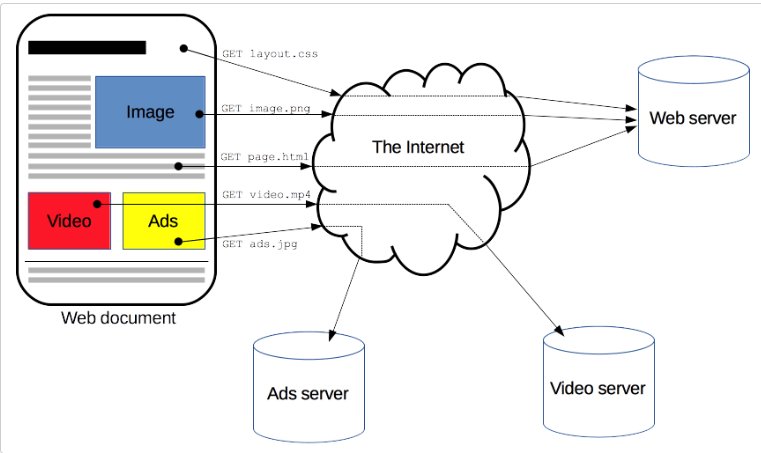 Kuva 1. yleiskuva, HTTP-protokollan toimintaperiaate.
Kuva 1. yleiskuva, HTTP-protokollan toimintaperiaate.
(lähde: https://developer.mozilla.org/en-US/docs/Web/HTTP/Overview)
HTTP-sanomien osat
HTTP-sanomat
Sekä pyyntö (request) että vastaus (response) ovat molemmat HTTP-sanomia ja niissä molemmissa on 4 osaa.
START LINE
- HTTP-sanoman aloitus riippuu siitä, onko kyseessä pyyntö vai vastaus
| URL | Pyyntö | Vastaus |
|---|---|---|
| https://www.lapinamk.fi/fi?vs_q=opinnot | GET /fi?ws_q=opinnot HTTP/1.1 | HTTP/1.1 200 OK |
| https://www.google.com?q=auto | GET /?q=auto HTTP/2 | HTTP/2 302 |
- Pyynnön startlinessa on näkyvillä HTTP-metodi sekä mahdolliset osoitteen 'alikansiot' ja parametrit (?ws_q=opinnot) sekä viimeisenä HTTP-protokollan versio
- Vastauksen startline sisältää vain HTTP:n version ja vastauksen statuskoodin esim. 200 OK
HTTP-metodeista, versioista ja statuskoodeista myöhemmin lisää.
HEADERS
Sekä pyyntö, että vastaus voivat sisältää useita headereita. Erilaisia headereita on niin paljon, ettei niitä käydä tässä vaiheessa yksitellen läpi vaan katsotaan myöhemmin käytännössä.
Joka tapauksessa pyynnön headereiden tarkoitus on tarjota metatietoa pyynnön tehneestä asiakassovelluksesta, ja taas vastaavasti vastauksen headereiden on tarkoitus tarjota metatietoa itse vastauksesta ja vastauksen lähettäneestä palvelusta
bash* Content-Type:text/html;charset=utf-8 (vastauksen formaatti ja merkistökoodaus) * Accept: */* (vastauksen hyväksytty MIME-Type) * Authorization: Bearer dfslkj3240824342kljw3342.3243243jl423k234.234xljflkfd (esimerkki JWT Bearer Tokenista pyynnön Authorization-headerissa, jolla pyynnön lähettänyt käyttäjä tunnistautuu serverille.) * Host: developer.mozilla.org (pyynnön header, josta selviää, mihin osoitteeseen pyyntö on lähetetty)* Content-Type:text/html;charset=utf-8 (vastauksen formaatti ja merkistökoodaus) * Accept: */* (vastauksen hyväksytty MIME-Type) * Authorization: Bearer dfslkj3240824342kljw3342.3243243jl423k234.234xljflkfd (esimerkki JWT Bearer Tokenista pyynnön Authorization-headerissa, jolla pyynnön lähettänyt käyttäjä tunnistautuu serverille.) * Host: developer.mozilla.org (pyynnön header, josta selviää, mihin osoitteeseen pyyntö on lähetetty)
BLANK LINE (TYHJÄ RIVI)
- Koska sekä pyynnössä että vastauksessa voi olla useita headereita, tyhjä rivi vain yksinkertaisesti toimii erottimena headereiden ja bodyn välissä
BODY
Body voi kuulua sekä pyyntöön että vastaukseen. HUOM HTTP:n GET- ja DELETE-metodeilla tehdyt pyynnöt eivät sisällä bodya ollenkaan GET:iä ja DELETE:ä käytettäessä kaikki palvelimelle tarvittava tieto pitää lähettää headereissa, evästeissä tai osana URLia joko pathin parametreina tai request parametreina
Vastaus sisältää lähtökohtaisesti aina bodyn, ellei vastauksen statuskoodi ole nimen omaan 204 NO CONTENT
20x-sarjan HTTP-statuskoodit tarkoittavat onnistunutta kyselyä. Koodia 204 voi käyttää esimerkiksi jotakin resurssia muokkaavan pyynnön vastauksena yksinkertaisesti ilmoituksena siitä, että muokkaus on onnistunut. Statuskoodeista lisää myöhemmin
HTTP-vastauksessa ei myöskään silloin ole bodya, jos metodina on HEAD tai OPTIONS
HTTP-versiot
Nykyään HTTP-protokollan versioita on 1.x, 2 ja 3. HTTP:n versio 1.1 julkaistiin vuonna 1997 ja se on ollut siitä asti standardi vuoteen 2015 asti, jolloin HTTP:n versio 2 julkaistiin.
HTTP/1.1
HTTP-protokolla 1.x toimii OSI-mallin sovellustasolla (Application Layer 7) ja se on rakennettu TCP-protokollan päälle, joka toimii vastaavasti OSI-mallin tiedonsiirtotasolla (Transport Layer 4). Tällä opintojaksolla keskitymme HTTP-protokollaan, mutta koska HTTP toimii TCP:n päällä, siitä on hyvä tietää vähän.
Ennen HTTP:n versiota 1.1 jokainen HTTP-pyyntö tarvitsi oman TCP-yhteyden palvelimelle. Tämä aiheutti tietoliikenteessä hitautta. Versiossa 1.1 otettiin käyttöön pysyvä (persistent) TCP-yhteys. Käytännössä tämä tarkoittaa sitä, että yhdessä ja samassa TCP-yhteydessä voi lähettää useita HTTP-sanomia. TCP-yhteyden pystyy 'pitämään hengissä' käyttämällä Connection-headeria antamalla sille arvoksi keep-alive. Lisäksi yhteyden pysyvyyteen voi vaikuttaa Keep-Alive-headerilla, jolle voi antaa timeout ja max arvot
bash
# Connection-header arvolla keep-alive käynnistää pysyvän TCP-yhteyden, jotta jokaista HTTP-sanomaa varten ei tarvitse
# avata omaa TCP-yhteyttä
Connection: keep-alive
# Keep-Alive-header arvoilla timeout=10, max=1000 tarkoittaa,
# että TCP-yhteys pysyy avoinna 10 sekuntia ilman uusia yhteyksiä
# (idle on 10 sekuntia), jonka jälkeen se sulkeutuu.
# max=1000 puolestaan tarkoittaa, että korkeintaan maksimissaan 1000 HTTP-pyyntöä voidaan hoitaa yhden TCP-yhteyden ollessa auki.
Keep-Alive: timeout=10, max=1000# Connection-header arvolla keep-alive käynnistää pysyvän TCP-yhteyden, jotta jokaista HTTP-sanomaa varten ei tarvitse
# avata omaa TCP-yhteyttä
Connection: keep-alive
# Keep-Alive-header arvoilla timeout=10, max=1000 tarkoittaa,
# että TCP-yhteys pysyy avoinna 10 sekuntia ilman uusia yhteyksiä
# (idle on 10 sekuntia), jonka jälkeen se sulkeutuu.
# max=1000 puolestaan tarkoittaa, että korkeintaan maksimissaan 1000 HTTP-pyyntöä voidaan hoitaa yhden TCP-yhteyden ollessa auki.
Keep-Alive: timeout=10, max=1000Pysyvästä yhteydestä huolimatta versiossa HTTP/1.1 pystyy lähettämään käytännössä vain yhden HTTP-sanoman kerrallaan per TCP-yhteys
Ongelmaa yritettiin ratkaista ns. pipelinellä, joka mahdollisti usean yhtäaikaisen HTTP-pyynnön lähettämisen yhdessä TCP-yhteydessä, mutta pipeline oli todella vaikea toteuttaa teknisesti, koska se vaati, että HTTP-vastaukset tulevat palvelimelta samassa järjestyksessä kuin pyynnöt on lähetetty. Vaikeasta toteutuksesta johtuen Firefox ja Chrome eivät tue pipelineä
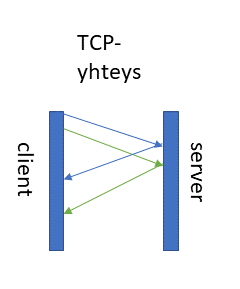
Havainnekuva pipelinen toteutuksesta
Jos pipelinen ensimmäisen HTTP-sanoman käsittely kestää 200 millisekuntia ja toisen HTTP-pyynnön käsittely kestää vain 100 millisekuntia, toinen olisi siis aiemmin valmis, mutta sen vastaanottaminen ennen 1. pyyntöä ei ole mahdollista.
Koska pipelineä ei tueta sen vaikean toteutuksen vuoksi, sen sijaan samalle palvelimelle avataan useampia yhtäaikaisia TCP-yhteyksiä (esim. Chromessa voi olla 6 TCP-yhteyttä yhtä aikaa auki samalle palvelimelle). Tämä toki noeputtaa nettisivujen resurssien latausta, mutta TCP-yhteyksien avaaminen ei ole nopeaa
ESIMERKKI USEAMMAN TCP-YHTEYDEN KÄYTÖSTÄ
INFO
Esimerkki on yksinkertaistettu, eikä siinä siksi oteta huomioon TCP-yhteyksien avausta tai palvelimen työskentelyaikaa. Tarkoitus on vain laskea tiedostojen latausajat.
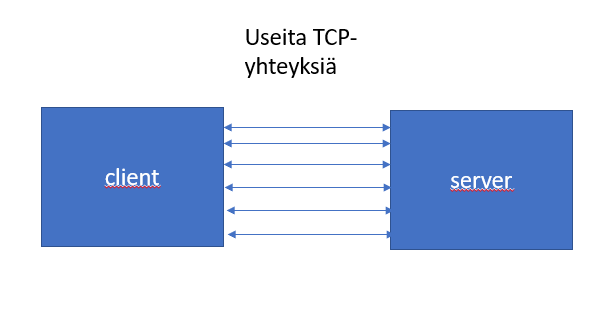
Jos tekemälläsi nettisivulla on esimerkiksi 10 JS- ja CSS-tiedostoa, joista jokaisen lataus kestää 100 millisekuntia, kestää näin ollen koko sivun lataus sekunnin (10*100=1000 ms), jos TCP-yhteyksiä olisi yksi kerrallaan auki.
Kun esim. Chrome voi avata 6 samanaikaista TCP-yhteyttä samalle palvelimelle kestää saman sivun lataus vain 200 ms. Lataus kestää ainoastaan 200 millisekuntia, koska ensimmäiset 6 tiedostoa tulevat 100 millisekunnin aikana. Jäljellä olevat 4 tiedostoa odottavat ensimmäisiä vapautuvia TCP-yhteyksiä ja latautuvat. Näin ollen kaikki 10 tiedostoa latautuvat 200 millisekunnissa.
HTTP/2
Lue lisää täältä
Kun nettisivujen koko kasvoi, kehitti Google vuonna 2009 SPDY-protokollan (Speedy). Sen tarkoituksena oli nopeuttaa pääasiassa sivujen latausta. Ensimmäiset testitulokset näyttivät jopa 55% parannusta latausaikoihin verrattuna HTTP/1.1:een, jonka jälkeen vuonna 2012 SPDY-protokollaa tukivat Chrome, Firefox ja Opera. Tämän jälkeen HTTP Working Group (HTTP-WG) aloitti virallisen HTTP/2:n kehittämisen SPDY:n pohjalta. Jonkin aikaa SPDY-projekti toimi virallisen HTTP/2:n testialustana, mutta lopulta vuonna 2015 Google laittoi SPDY:n jäihin.
Suurimpia parannuksia HTTP/1.1 olivat pyyntöjen ja vastausten
- multiplexing ja server push
- priorisointi
- headereiden pakkaaminen / pienentäminen
MULTIPLEXING
HTTP/1.1 tukee pipelineä, joka mahdollistaa useamman HTTP-sanoman lähettämisen samassa TCP-yhteydessä, mutta selaimet eivät tue pipelineä, koska se on käytännössä vaikea toteuttaa
INFO
Pipeline vaati, että vastaukset pyyntöihin tulevat siinä järjestyksessä kuin pyynnöt on lähetetty.
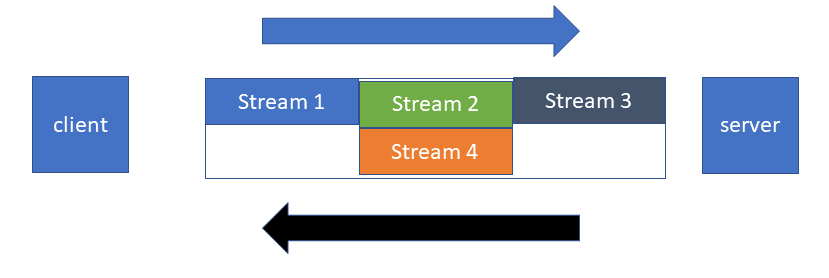
Havainnekuva HTTP/2:n multiplexingistä
HTTP/2:n binary frame buffer ja streamaus mahdollistavat sen, että yhdessä ja samassa TCP-yhteydessä voi lähettää useamman HTTP-sanoman, eikä niiden järjestys tarvitse olla sama tullessa ja mennessä.
Binary Frame Buffer
HTTP/1.x kaikkien HTTP-sanomien headerit ja bodyt kulkevat selkokielisenä tekstinä. HTTP/2 on semanttisesti samanalainen kuin edeltäjänsä, eli siinä on samat HTTP-metodit, headerit yms., mutta sanomat on jaettu pienempiin palasiin (frameihin) ja framet ovat binäärimuodossa.

SERVER PUSH
INFO
HTTP/2:n Server Push-ominaisuus 'rikkoo' perinteisen HTTP:n pyyntö/vastaus-periaatteen. Server Push tarkoittaa käytännössä sitä, että palvelin voi lähettää asiakassovellukselle tietoa asiakkaan erikseen sitä pyytämättä.
Perinteisesti selaimet rendaavat HTML-sivujen sisällön ylhäältä alaspäin. Katso alla oleva esimerkki
html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<!-- ulkoiset tyylitiedostot ladataan headerissa, jotta ne ovat mukana ja vaikuttavat bodyn tyyleihin -->
<link rel="stylesheet" href="styles.css">
</head>
<body>
<p>fdlskjfsdlkfsdjsdflksfd fsdlkjfdslfdsjdsfl</p>
<!-- JS-riippuvuudet kannattaa ladata viimeisenä ennen bodyn lopetusta
näin JS-tiedostot liitetään dokumenttiin vasta bodyn jälkeen,
eikä näin blokkata sisällön rendausta selaimelle.
Jos mysqcripts.js-tiedosto olisi html-sivun head-tagissa, sen lataus
blokkaisi sivun rendauksen
-->
<script src="myscripts.js"></script>
</body>
</html><!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<!-- ulkoiset tyylitiedostot ladataan headerissa, jotta ne ovat mukana ja vaikuttavat bodyn tyyleihin -->
<link rel="stylesheet" href="styles.css">
</head>
<body>
<p>fdlskjfsdlkfsdjsdflksfd fsdlkjfdslfdsjdsfl</p>
<!-- JS-riippuvuudet kannattaa ladata viimeisenä ennen bodyn lopetusta
näin JS-tiedostot liitetään dokumenttiin vasta bodyn jälkeen,
eikä näin blokkata sisällön rendausta selaimelle.
Jos mysqcripts.js-tiedosto olisi html-sivun head-tagissa, sen lataus
blokkaisi sivun rendauksen
-->
<script src="myscripts.js"></script>
</body>
</html>HTTP/2:n server push-ominaisuuden ansiosta palvelin voi 'pukata' body-tagin alalaidassa liitetyn myscript.js:n ennen kuin selain edes pyytää sitä. Näin sivujen lataus nopeutuu.
STREAM PRIORITIZATION (PRIORISOINTI)
Koska HTTP-sanomat voidaan binary frame bufferoinnin ja streamauksen ansiosta jakaa pienempiin osiin ja lähettää vaihtelevassa järjestyksessä, tämä mahdollistaa eri resurssien latauksen priorisoimisen.
Prioriteettiin pystyy vaikuttamaan esim. JavaScriptin fetch-APIn RequestInit-objektin priority-attribuutilla
js
fetch('/api/data', {
priority: {
weight: 32
}
})
.then(response => {
// Handle the response
})
.catch(error => {
// Handle the error
});fetch('/api/data', {
priority: {
weight: 32
}
})
.then(response => {
// Handle the response
})
.catch(error => {
// Handle the error
});Prioriteetin painoarvo voi olla välillä 1-256. Mitä suurempi luku, sen isompi painoarvo resurssilla on.
fetchpriority
Myös tietyille HTML-tägeille, kuten kuville voi antaa fetchpriority-attribuutin. Can I use-sivun mukaan attribuutti on ainakin toistaiseksi 'experimental' ja siksi huonosti tuettu eri selaimissa (https://caniuse.com/?search=fetchpriority)
HEADEREIDEN PAKKAUS
HTTP/1.x headerit kulkevat jokaisen requestin mukana tekstimuodossa. HTTP/2:ssa headerit ovat frameissa, jotka ovat binäärimuodossa ja lisäksi käyttäen HPAC-pakkausmentelmää HTTP/2:ssa pystytään vähentämään samojen headereiden määrää sanomien lähetyksessä.
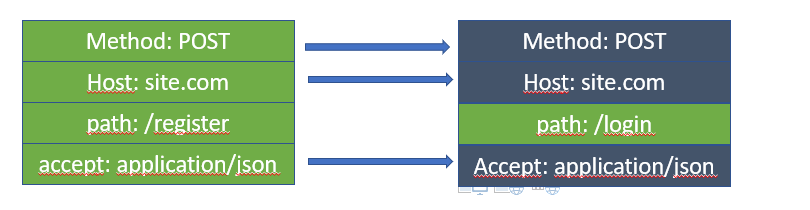
Yksinkertaistettu havainnekuva headereiden pakkauksesta
Yo. kuvassa on kaksi erillistä requestia, joista ensimmäisellä. (vasemmalla) rekisteröidytään järjestelmään (path on /register) ja toisella (oikealla) kirjaudutaan sisään. Näin ollen kahden requestin välillä vaihtuu vain path, eikä muita samoja headereita tarvitse lähettää uudelleen.
HTTP/3
HTTP/3 on julkaistu heinäkuussa 2022. Sovelluskerros (HTTP) on semanttisesti edeltäjiensä kaltainen, mutta versioissa 1.x ja 2 käytössä ollut TCP-protokolla (Tiedonsiirtokerros) on korvattu QUIC-protokollalla, joka pohjautuu UDP:hen. Tiedonsiirtoprotokollat, kuten TCP ja UPD menevät tämän opintojakson fokuksen ohi, eikä niitä käydä tarkemmin läpi, mutta HTTP/3:ssa on käytössä UDP koska se on TCP:tä nopeampi. UDP on nykyäänkin käytössä esim. videostriimauksesssa ja nettipeleissä, joissa nopeus on tärkeämpi kuin sanomien eheys.
HTTP-METODIT
HTTP-metodit, joita joskus kutsutaan myös HTTP-verbeiksi ovat HTTP-pyyntöjen tapoja kommunikoida palvelimen resurssien kanssa. Esimerkiksi kaksi eri pyyntöä samaan resurssiin (URLiin) tuottavat eri tuloksen, kun pyynnöillä on eri metodi Tästä lisää Rest-kappaleessa.
Mikä tarkoitaa, kun HTTP-metodi on turvallinen?
Jos HTTP-metodi on turvallinen, se on vain-luku -tyyppinen, eli se ei muokkaa palvelimen resursseja
Mikä tarkoitaa, kun HTTP-metodi on idempotentti?
Jos HTTP-metodi on idempotentti, se tarkoittaa, että sen vaikutus palvelimen tilaan on aina sama (samoilla parametreilla), vaikka pyyntö tehtäisiin useita kertoja. Näin ollen kaikki turvalliset HTTP-metodit ovat myös idempotentteja
Huomaa, että idempontenttisuus on suhteessa palvelimen tilaan. Tämä tarkoittaa siis, että
- jos teet kyselyn osoitteeseen /users ja saat vastauksena listan, jossa on 10 käyttäjää
- poistat sen jälkeen 1 käyttäjän ja
- teet uuden kyselyn saat listan käyttäjistä, mutta tällä kertaa siinä onkin vain 9 käyttäjää
Käyttäjien (tai minkä tahansa pyydettävän resurssin) lukumäärä voi vaihdella, mutta saat joka kerta listan käyttäjistä, vaikka teet saman kyselyn 100 kertaa peräkkäin
Mikä tarkoitaa cachetettavissa?
Pyynnön vastaus on cachetettavissa, jos
- itse HTTP-metodi on cachetettavissa. Ainoat cachetettavat metodit ovat GET ja HEAD.
- statuskoodi on cachetettavissa (cachetettavat statuskoodit ovat 200, 203, 204, 206, 300, 301, 404, 405, 410, 414 ja 501)
- vastauksessa ei ole cachetuksen estävää headeia (kuten esim. Cache-Control: no-cache)
GET
GET-metodi hakee pyydetyn tiedon. GET on vain-luku -tyyppiä. ÄLÄ KOSKAAN KÄYTÄ GET-METODIA MUOKKAAVIIN KYSELYIHIN
| Pyynnöllä on body | Ei |
| Vastuksella on body on body | Kyllä |
| Turvallinen | Kyllä |
| Idempotentti | Kyllä |
| Cachetettavissa | Kyllä |
| Voidaan käyttää HTML-formissa | Kyllä |
HEAD
Head toimii niin kuin GET-metodi, mutta vastauksella ei ole bodya. Sitä voi käyttää esim. ennen varsinaista tiedoston latausta kysymään tiedoston koko HTTP-vastauksen Content-Length-headerista lataamatta itse kuvaa
| Pyynnöllä on body | Ei |
| Vastuksella on body on body | Ei |
| Turvallinen | Kyllä |
| Idempotentti | Kyllä |
| Cachetettavissa | Kyllä |
| Voidaan käyttää HTML-formissa | Ei |
POST
Aikoinaan HTTP-metodeja oli vain 2 (GET ja POST). GET-metodia käytettiin datan lukemiseen palvelimelta ja POST-metodia käytettiin datan lisäämiseen ja olemassa olevan datan muokkaamiseen ja poistamiseen. Nykyään kuitenkin POSTin päätarkoitus on lisätä uutta dataa palvelimelle. Olemassa olevan datan muokkaukselle ja sen poistolle on olemassa omat metodinsa.
Koska POST-metodilla voi lähettää dataa palvelimelle, sillä on body toisin kuin GETillä. POST-pyynnön bodyn tyyppi osoitetaan pyynnön Content-Type-headerilla
| Pyynnöllä on body | Kyllä |
| Vastuksella on body on body | Kyllä |
| Turvallinen | Ei |
| Idempotentti | Ei |
| Cachetettavissa | On mahdollista toteuttaa tietyin reunaehdoin, mutta ei kannata |
| Voidaan käyttää HTML-formissa | Kyllä |
POST-metodi ei ole turvallinen, koska ei ole vain-luku -tyyppinen. POST ei ole myöskään idempontentti, koska sitä käytetään uuden datan lisäämiseen palvelimelle ja näin ollen muuttaa joka kerta palvelimen tilaa.
PUT
PUT-metodia käytetään nykyään palvelimella olevan datan muokkaukseen. PUT-metodia voi käyttää myös ns. 'UpdateOrInsert'-tapauksessa, jossa uusi tieto lisätään, jos sitä löydy, ja päivitetään annetuilla tiedoilla, jos se on jo olemassa.
| Pyynnöllä on body | Ei |
| Vastuksella on body on body | Voi olla |
| Turvallinen | Ei |
| Idempotentti | Kyllä |
| Cachetettavissa | Ei |
| Voidaan käyttää HTML-formissa | Ei |
PUT-metodin pyynnön bodyyn tulee yleensä se uusi data, jolla valitun resurssin olemassa oleva data halutaan korvata. PUT ei ole turvallinen, koska se tekee muutoksen palvelimelle, mutta siitä huolimatta se on idempontentti. PUT on idempotentti siksi, että joka kerta data muuttuu, mutta vain 1. kerralla on vaikutusta, kaikki muut kerrat muuttavat datan siihen, mitä ne 1. kerran jälkeen ovat. PUT-pyynnöt eivät ole cachetettavissa ja niiden jälkeen cachetetut datat pitää invalidoida aina. PUT-vataus voi sisältää bodyn, mutta se ei ole pakollista, koska monesti 204 NO CONTENT on riittävä vastus
DELETE
DELETE-metodia käytetään resurssien poistoon
| Pyynnöllä on body | Voi olla |
| Vastuksella on body on body | Voi olla |
| Turvallinen | Ei |
| Idempotentti | Kyllä |
| Cachetettavissa | Ei |
| Voidaan käyttää HTML-formissa | Ei |
Vaikka DELETE-pyynnössä voi olla body, jos Content-Length-header on määritetty ÄLÄ KÄYTÄ IKINÄ BODYA DELETE-pyynnössä. Tarkemmn speksin DELETE-metodista voit lukea täältä: RFC9110
PATCH
PATCH-metodia käytetään olemassa olevan datan muokkaukseen niin kuin PUT-metodiakin, mutta PATCHilla voidaan muokata vain osaa resurssista siinä missä PUTin tarkoitus on päivittää kaikki resurssin tiedot
| Pyynnöllä on body | Ei |
| Vastuksella on body on body | Voi olla |
| Turvallinen | Ei |
| Idempotentti | Ei |
| Cachetettavissa | Ei |
| Voidaan käyttää HTML-formissa | Ei |
Koska PATCH-metodilla voidaan muokata vain osaa resurssista, se ei voi olla idempotentti
STATUSKOODIT
HTTP-tilakoodit voidaan jakaa viiteen ryhmään
- 100 (100-199) Informatiiviset
- 200 (200 - 299) Onnistui
- 300 (300 399) Uudelleenohjaus
- 400 (300 - 499) Asiakas teki virheen
- 500 (500 - 599) Palvelin teki virheen
200 (OK)
- GET-metodin tapauksessa 200 tarkoittaa, että pyydetyt tiedot tulivat perille palvelimelta
- POST ja PUT uusi lisätty / olemassa oleva muokattu resurssi saadaan vastauksen bodyssa
204 (NO CONTENT)
- esim. PATCH-pyynnön jälkeen päivitetyn tiedon lähettäminen takaisin palvelimelta ei aina ole tarpeellista, koska asiakassovellushan tietää, mitä tietoja palvelimelle on lähetetty. Tällaisessa tapauksessa pelkästään 204 riittää osoittamaan, että tietojen päivitys onnistui
301 (Moved Permanently)
Resurssin URL on vaihtunut
302 (Found) JA 307 (Temporary Redirect)
302 tarkoittaa, että pyytämäsi resurssi on olemassa ja se löytyi, mutta sinut ohjattiin hetkeksi toiselle sivulle. Tämä toinen sivu voi olla vaikka Googlen tietosuojan hyväksyminen. Tässä tarvitaan apuna Location-header, jonka arvoksi voi tulla URL, johon käyttäjä ohjataan. Siihen voi lisätä mm. esim. redirect-urlin, johon käyttäjä ohjataan takaisin tietosuojalausunnon hyväksymisen jälkeen
307 on semanttisesti sama kuin 302, sillä erotuksella, että 307:n pyynnön HTTP-metodi ei saa vaihtua.
400 (Bad Request)
Palvelin ei suostu käsittelemään pyyntöä, koska asiakas on tehnyt jonkin virheen (esim. syntaksivirhe)
401 (Unauthorized)
Virheen nimi on unauthorized, mutta semanttisesti se on sama kuin unauthenticated. Autentikoinnista ja autorisoinnista lisää myöhemmin.
403 (Forbidden)
Tämä virhe on semanttisesti unauthorized. Eli käyttäjä on kyllä kirjautunut sisään (autentikoitunut) järjestelmään, mutta hänellä ei ole oikeutta tarkastella jotakin resurssia, koska esim. oikeudet eivät riitä siihen, tai tarkasteltava resurssi on toisen käyttäjän omistuksessa.
405 (Method Not Allowed)
Tämä on virhe, jota näkee varsinkin Rest-Apeissa paljon. Se tulee esim. siloin, kun yrität tehdä DELETE-pyyntöä apin endpointiin, johon DELETE-pyynnön lähettäminen ei ole sallittu.
500 (Internal Server Error)
Geneerinen palvelimen päässä tapahtunut virhe
501 (Not Implemented)
Voit lähettää vastauksen palvelimelta 405-koodilla, kun asiakkaan tekemän pyynnön metodi ei ole sallittu. Taas vastaavasti 501-statusta voi käyttää siihen, kun DELETE on tarkoitus ottaa käyttöön, mutta ominaisuutta ei ole vielä implementoitu, eikä sitä siksi voida ottaa vielä käyttöön.
COOKIES (EVÄSTEET)
Lue lisää!
esim. täältä: https://developer.mozilla.org/en-US/docs/Web/HTTP/Cookies
Evästeet ovat pieniä tekstiteidostoja, jotka palvelin voi lähettää selaimelle. Evästeet tallennetaan selaimeen ja lähetetään takaisin palvelimelle osana HTTP-pyyntöjä. Evästeitä ei kannata käyttää ns. 'leipätekstisisällön' välittämiseen selaimelle, vaan niissä voi lähettää samalla tavalla metatietoa asiakkaasta kuten headereillakin.
Perinteisesti evästeiden käyttöön on 3 syytä
- käyttäjän tunnistaminen (autentikointi)
- sisällön personointi
- esim. tumma / vaalea teema
- käyttötottumusten seuraaminen
INFO
Näistä tällä opintojaksolla tarkastelemme käyttäjän autentikointia, josta lisää myöhemmin, mutta tutkitaan nyt evästeiden ominaisuuksia.
Kun palvelin lähettää evästeen selaimelle osana HTTP-vastausta, vastauksessa on Set-Cookie-header
bash
Set-Cookie:cookie_name=cookie_value
Set-Cookie: session_id=32423484324Set-Cookie:cookie_name=cookie_value
Set-Cookie: session_id=32423484324Eri ohjelmointikielillä on myös erilaisia implementaatioita, joiden avulla evästeitä voi asettaa
python
res = Response()
res.set_cookie('session_id', '23434283243249234243')
return resres = Response()
res.set_cookie('session_id', '23434283243249234243')
return resKun selain lähettää HTTP-pyynnön mukana evästeen takaisin palvelimelle, siihen käytetään Cookie-headeria
bash
Cookie: session_id=234087324324; another_cookie=sfdlksdfj243Cookie: session_id=234087324324; another_cookie=sfdlksdfj243Monissa ohjelmointikielissä on erialisia tapoja päästä HTTP-pyynnön evästeisiin käsiksi palvelimen päässä
js
// tämä routehandler käsittelee HTTP-pyynnöt,
// jotka lähetetään urliin: http://localhost:5000/api/v1/account
const accountRouteHandler = async (request, response) => {
let cookies = request.cookies;
// tämän jälkeen voit tehdä evästeille, mitä haluat
// esim. hakea sisäänkirjautuneen käyttäjän tietokannasta
let sessoion_id = cookies['session_id']
if session_id != null {
let account = await userService.getUserBySessionId(session_id.value())
if account == null {
return response.json({err: 'unauhtorized'}, status_code=401)
}
return response.json({account})
}
return response.json({err: 'unauthorized'}, status_code=401)
}// tämä routehandler käsittelee HTTP-pyynnöt,
// jotka lähetetään urliin: http://localhost:5000/api/v1/account
const accountRouteHandler = async (request, response) => {
let cookies = request.cookies;
// tämän jälkeen voit tehdä evästeille, mitä haluat
// esim. hakea sisäänkirjautuneen käyttäjän tietokannasta
let sessoion_id = cookies['session_id']
if session_id != null {
let account = await userService.getUserBySessionId(session_id.value())
if account == null {
return response.json({err: 'unauhtorized'}, status_code=401)
}
return response.json({account})
}
return response.json({err: 'unauthorized'}, status_code=401)
}Jos teet esim. js-clientiä, jossa käytät pyyntöjen lähettämiseen fetch-APIa, saat evästeet mukaan pyyntöön näin:
js
// lähetetään pyyntö accountRouteHandlerille
fetch('http://localhost:5000/api/v1/account', {
credentials: 'include', // tämä rivi
})
.then(resp => resp.json())
.then(account => console.log(account))// lähetetään pyyntö accountRouteHandlerille
fetch('http://localhost:5000/api/v1/account', {
credentials: 'include', // tämä rivi
})
.then(resp => resp.json())
.then(account => console.log(account))Istuntoeväste (session_id) pitää lähetää palvelimelle jokaisen pyynnön mukana, johon käyttäjän pitää olla tunnistautunut, koska HTTP on tilaton protokolla.
Tilaton protokolla
Tilaton protokolla tarkoittaa sitä, että palvelin käsittelee jokaisen sille saapuvan pyynnön omana kokonaisuutenaan, eikä suhteuta uutta pyyntöä mitenkään edellisiin.
Tilattomuus näkyy koodatessa käytännössä siten, että kirjautumisen jälkeen istuntoeväste pitää lähettää kaikkien pyyntöjen mukana palvelimelle tai palvelin ei tunnista pyynnön tekijää. Palvelin ei siis pidä kirjaa siitä, että koska edellisen pyynnön aikana käyttäjä kirjautui sisään niin automaattisesti kaikki seuraavat pyynnöt tulevat samalta käyttäjältä
Web-palvelin on kuin dementikko, joka ei muista sekunti sitten käytyä keskustelua (edellistä pyyntöä) ja siksi tunnistautuakseen käyttäjän (selaimen) pitää aina muistuttaa palvelinta siitä, kuka hän on.
Onko evästeitä sitten pakko käyttää tunnistautumiseen?
Ei ole. teknisestä näkökulmasta palvelinta ei kiinnosta, miten käyttäjä tunnistautuu! Voit esimerkiksi toteuttaa tunnistautumisen lähettämällä jokaisen pyynnön yhteydessä oman käyttäjätunnuksen ja salasanan ja palvelin on tähän täysin tyytyväinen. istuntotunnisteen lähettäminen evästeessä on kuitenkin paljon turvallisempaa kuin käyttäjätunnuksen ja salasanan lähettäminen joka kerta.
Voit lähettää istuntotunnisteen myös esim. Bearer tokenina osana Authorization-headeria Kuitenkin silloin, kun tehdään selainsovellusta, on luonnollista ja helpointa käyttää eästeitä tunnistautumiseen.
LIFETIME
Evästeiden voimassaoloaikaa voi rajoittaa Expires-avaimella
bash
Set-Cookie: session_id=a3fWa; Expires=Thu, 31 Oct 2021 07:28:00 GMT;Set-Cookie: session_id=a3fWa; Expires=Thu, 31 Oct 2021 07:28:00 GMT;Etenkin istuntoevästeille kannattaa antaa kohtuullisen lyhyt voimassaoloaika.
EVÄSTEIDEN PÄÄSYRAJOITUKSET
Etenkin tunnistautumiseen kannattaa käyttää evästeitä selainsovelluksissa, koska evästeisiin pääsyä voi rajoitaa, mutta headereihin pääsee käsiksi ilman rajoituksia
INFO
Authorization-headerin lähettäminen on kuitenkin turvallista HTTPS:n yli, koska kaikki sanomassa (headereista lähtien) on salattu.
Secure
- jos teet istuntoevästeen, joka on Secure, se lähtee HTTP-pyynnön mukana vain, jos osoite on https://....
- tällaista suojamekanismia ei ole headereilla, vaan koodarin pitää itse huolehtia siitä, että Authorization-header ja siihen liitetty istuntotunniste eivät ns. 'liiku' eteenpäin suojaamattoman yhteyden yli
HttpOnly
- HUOM! tämä ei tarkoita sitä, että eväste lähtetään vain silloin palvelimelle pyynnön mukana, kun protokolla on http.
- jos teet istuntotunnisteen, joka on HttpOnly, sitä ei voi lukea JavaScriptilla ollenkaan, mikä parantaa tietoturvaa
- jos esimerkiksi sivustosi on kaapattu ja hyökkääjä on saanut XSS-hyökkäyksen avulla injektoitua sivuston lähdekoodiin JS:ää, hän ei pysty varastamaan istuntotunnistettasi, koska evästettä ei voi lukea JS:llä.
Domain
- jos Domain-attribuuttia ei ole evästeessä, se voidaan lähettää vain sille palvelimelle (hostille), joka sen on luonut
- jos Domain-attribuutti löytyy esim. Domain=example.com, keksi lähetetään myös sen alidomaineihin (esim. api.example.com)
SameSite
Tämä ei ole sama kuin Domain-attribuutti
Domain-attribuutilla pystytään vaikuttamaan mille hosteille eväste voidaan lähettää
SameSite-attribuutti vaikuttaa siihen domainiin, mistä pyyntö on tehty (ei siis hostiin, vaan clientiin.)
SameSite-attribuutilla on 3. eri arvoa:
Strict
- Kun SameSite on Strict, eväste voidaan lähettää ainoastaan pyyntöjen mukana, jotka lähetetään samasta osoitteesta kuin missä se eväste on luotu
LAX (oletusarvo)
- Kun SameSite on Lax, periaate on sama kuin Strictissä. Eli selain lähettää evästeen vain, jos pyyntö lähtee samasta osoitteesta kuin missä eväste on luotu, mutta Lax sallii evästeen lähetyksen mm. navigoitaessa sivulle muualta (ulkoisen linkin kautta)
None
- None-valinnalla SameSite on käytännössä pois päältä ja evästeet voidaan lähettää kahden eri domainin välillä
- Huomaa, että jos tämä on valittu, Secure-attribuutin on pakko olla päällä.
SameSite on hyvä tapa suojautua CSRF-hyökkäyksiä vastaan, koska sen avulla palvelin voi varmistua siitä, että sille tulevat pyynnöt tulevat sieltä, mistä niiden pitääkin
Istuntoevästeen kannattaa lähtökohtaisesti olla
- Secure
- HttpOnly
- sekä SameSite joko Lax tai Strict, mikäli mahdollista